stanlyn said:
It appears to me that your way would cause the system to wait until the batch of 20 completes.. If so, then all we need is a single whois request to take 20-30 seconds and performance is killed.
No, All a max process cap does is only start as many in parallel, if one of them finishes it can immediately be replaced by another process, so why do you think this waits for a batch of processes to all finish.
The number of currently running processes is limited by a max value that's also not fixed, but adapts to what makes sense, therefore the measurement of something that's useful to detect what's making the overall processing fastest. As I said again and again the throughput.
Do you start to get the idea?
stanlyn said:
Why would you do that as the whois is already generating the response file which is a single file per record.
Please, read more thoroughly what I write. I said the VFP process controlling all this can generate an empty file. This file therefore will have a file creation timestamp that's BEFORE the whois process even starts, thus measuring the start time of the process, which is lost if you would just measure the file creation time that's caused by whois starting AFTER it has started. That way you DO get how much more processes could cause new process starts to take longer. Remember any OS has to share CPU time to all running processes. More processes don't run faster and also the start of a process is, well, a process in itself. A process that can take longer just because so many processes already run.
Taking the full time duration means you measure the time spent on the whois request, not just the net internal time. Well, there's perhaps one bit to add, the time you take after detecting a closed file you can read to putting it's content somewhere else, into a database, perhaps. But that wouldn't need to count in the interval between last write access to you detecting this as complete file. It's not time wasted but time spent on other things like starting a process or looking through all currently existing output files.
You could also decide to leave all files as is and process them after all whois are through, as that means you can concentrate on the whois calls, processing lots of files with uch data to a database server shrinks your network bandwidth for the whois repsonses, so is counterproductive.
stanlyn said:
What if 5 of this batch takes 20 seconds each?
Then a measure like suggested, the throughput of the last 5 whois requests (notice that's a moving window, with the next finished request one of the five falls out). In the worst case you judge this five unfortunate requests as a bad performance, reduce the number of processes to find out in 10 requests this can get faster again with more processes. You adjust - and that's important at least to me - to a current performance only measured from things that happend currently, not 5 hours ago when the whole system was in another state perhaps also serving data to clients or whatever happend then that reduced the performance, or perhaps was better than now.
So mainly the difference between your and my way of running this is that you work with a fixed number of processes (at least you say and think, maybe you even start more processes than you're aware of, that's another thing to verify by measuring it) while I - to come back to our difference - while I would let the system adapt this max number of concurrent processes by the experience about how they perform.
And to finish the thought, in doing so I don't just optimize the performance, I prevent situations where I already see in advance more processes make the whole system slower and then unstable until it may crash. If there is a bottleneck at some time that may not be caused by the server itself but by an internet quirk or several servers reacting with exceed limits, then this adjustment may also from time to time become too cautious, but it's also a matter of experience what to measure and how to react to it in detail.
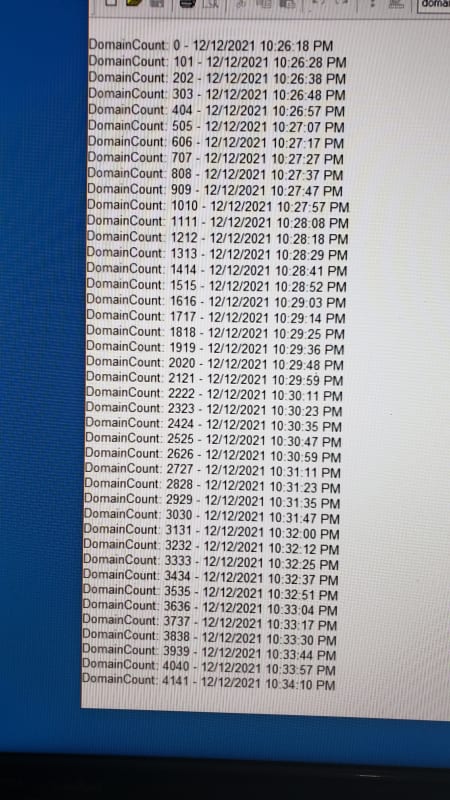
From all my tests the end phase where no process is started and the already running processes finish one after the other, the performance peeks, which alone shows me that starting processes is a bottleneck which I didn't see coming. At that phase my algorithm was increasing the max allowed process count, which then wasn't used, as there where no further requests. At that time the whole system could also loop back and restart with the first whois to continuously go through all the domains and get the information as frequently as possible.
It's a matter of several development iterations to see what measures make most sense, for example you could also take the knowledge of the expected size of the whois response of a domain you already checked to see whether it performed as usual, better, or worse and take that into account for the control of how many things to run in parallel.
Again, I don't see why you think controlling the number of concurrent processes means starting that number and waiting for all of them to finish. As I said once a process ends and you can get its output file, you decrease the number of currently running processes by one, which allows to start another. At least if the current max cap stayed or even grew. And if it shrinked, then you have to wait for further processes to finish until the current number goes below the max cap, but that's just done when you detect that current performance went down.
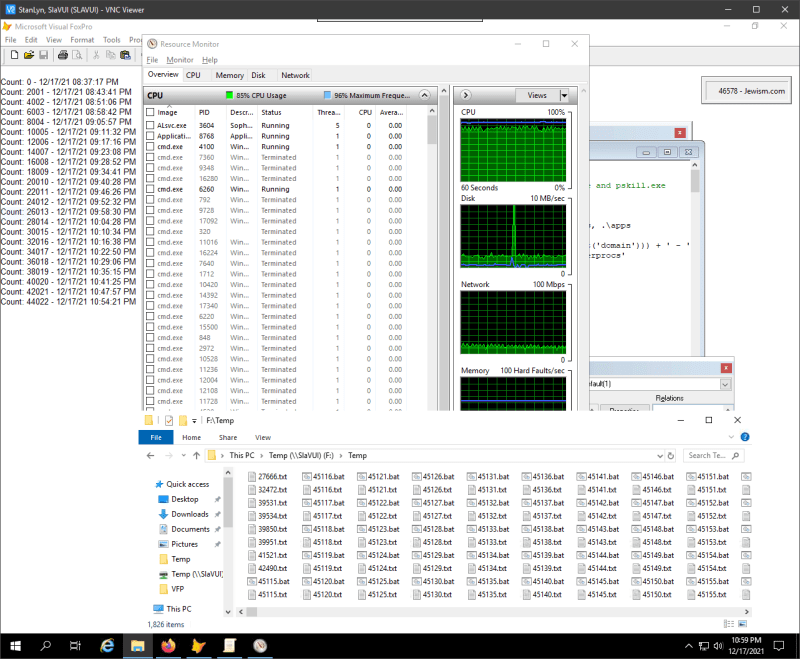
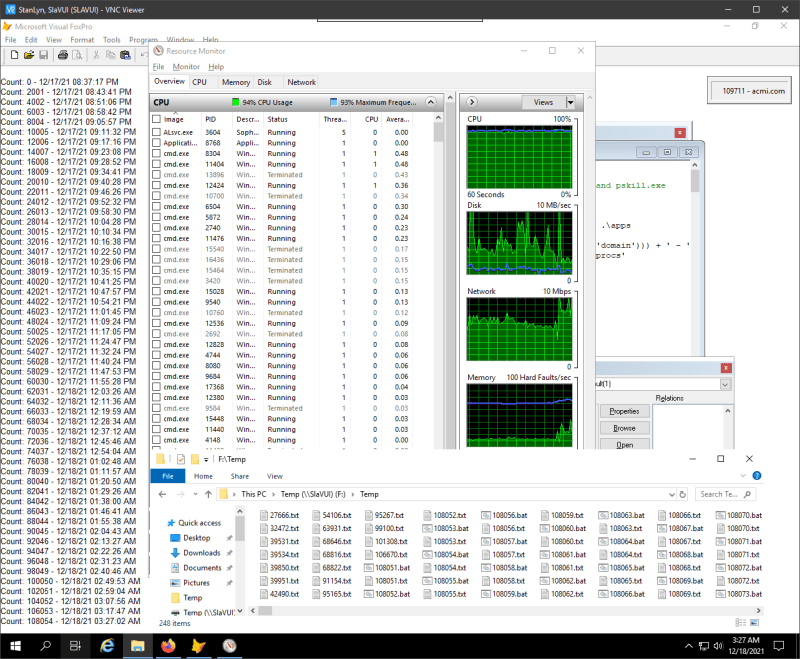
It seems you think along the lines that the major time is spent at the whois servers anyway and the rest is quite constant. Well it isn't There are times the parallel output of files causes disk writes to take longer than when les processes try to write. This could also be optimized by using raid or multiple drives.
I introduced a minimum process count too, so that maximum process cap never goes down to 0. At any time at least that many processes run in parallel. because of course when the current number sinks below max you dont need to wait for all current processes to finish, who said that? I thought of that happening in your approach, in the way you described it you run a batch of N whois and then continue by starting another N, not saying anything about the way you react to finished processes this actually means and still means that you would start all requests. You were saying by the time you have started N some of them have already finished. Yes, of course, but likely not all and when you continue starting this just jams your queue.
The core loop should looks for finished outputs and then triggers a new process (if allowed) and evaluates the found result(s). And as you start at 0 processes this same main loop logic finds that it can immediatley start max cap number of processes. In parallel, of course. I don't know why you still don't see that logic working. It really just needs a counter that in and decreases a max cap, a min cap, too perhaps, to never drop down to 0, and also you don't have to change the max cap drastically just because of the current measurement. You could define a trend that starts at 0 and gets incremented. That increment doesn't even need to be an integer, it could be something like increasing the max cap by 0.5 more processes per second, and when that leads to worse throughput you don't steer hectically in the other direction but let the trend sink in .01 steps, whatever turns out to be the best feedback loop.
Still, it mainly is maintaining one counter of currently started and not yet finally processed requests plus a max cap to watch over and a measurement of the performance with these variables, no rocket science. In short this means when you would run 10 tests with 10 different N values, then the way I suggest this will vary N itself over night. You can later also analyze a log to see which number of processes was average during a night and make that the best guess for the starting number. You could see whether the process count has a tendency to oscillate instead of converging to an optimium. And you might be able to see what else in the system causes the performance of your appication to change, be it as simple as Windows downloading update to then wait for you to allow to install them. There always is a multitude of things happening to a system even if you devote it to running your whois list and nothing else during night.
Chriss