Jan Flikweert
Programmer
Hi all,
I hope I spelled the word sequential files correct.
I attached an example of this kind of files. How to read this in VFP? Line by line filetostr seems not to be the option. wscript.shell stdin read is also not clear and not well documented.
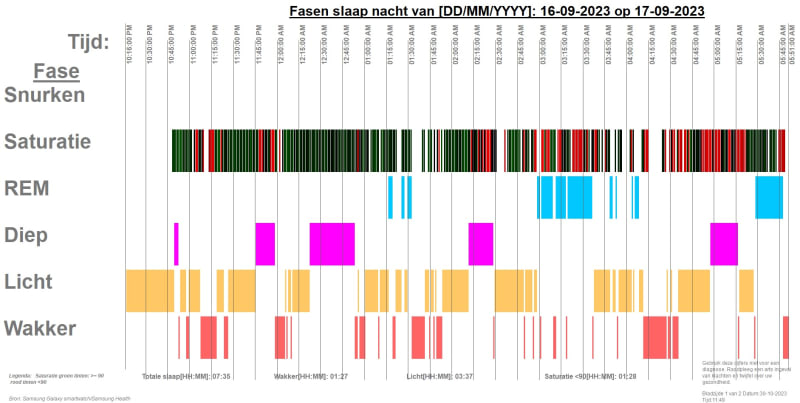
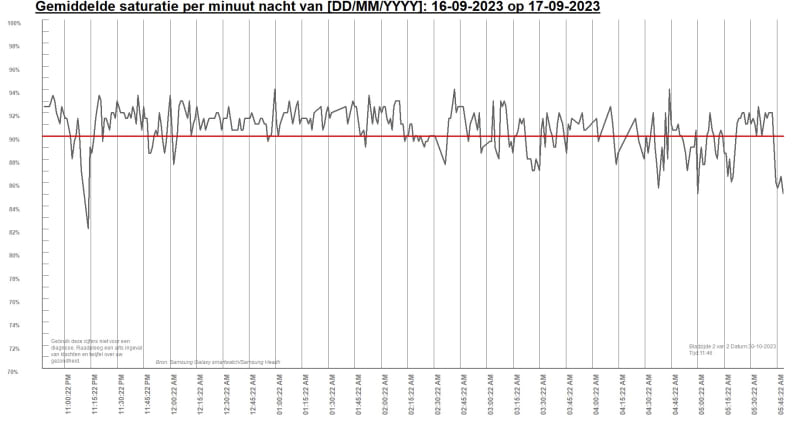
This is a file from the open source program OSCAR. And it contains data from my personal CPAP device regarding sleep apnea.
Kind regards,
Jan Flikweert
I hope I spelled the word sequential files correct.
I attached an example of this kind of files. How to read this in VFP? Line by line filetostr seems not to be the option. wscript.shell stdin read is also not clear and not well documented.
This is a file from the open source program OSCAR. And it contains data from my personal CPAP device regarding sleep apnea.
Kind regards,
Jan Flikweert