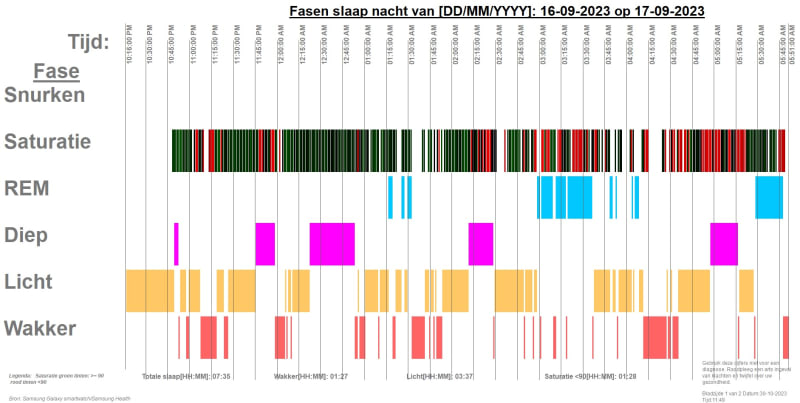
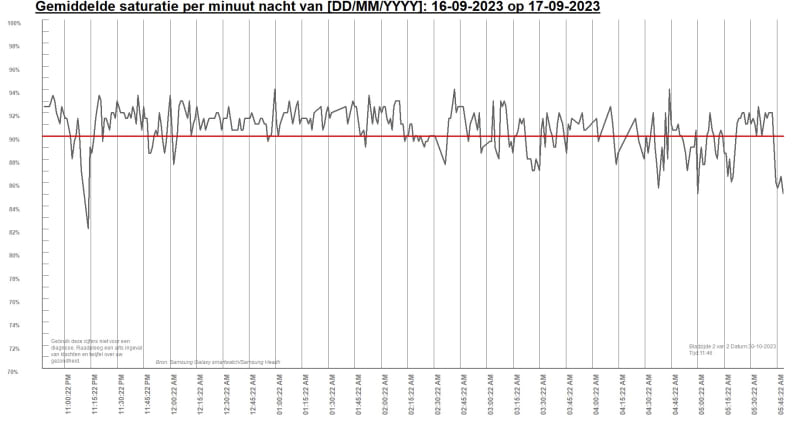
You mention the files are EDF, well that's an important detail, isn't it?
Well, The link I gave points out OSCAR is "exploring data produced by CPAP and related machine" and the description text says "or the viewing of the high-resolution sleep data that is generated by the CPAP and stored on the SD card"
So there are files on the SD card, and by what you say they are EDF format files. Searching for CPCP files I came across
which also points out EDF and links wikipeadia
Which in turn points to
with specs (specifications) in
So now you have some pointers about what this is, not only sleep data, but a binary format for time series data of many different things, not only sleep data. It's not just, as you expect a series of numbers with a fixed byte length. I mean how could it, there would at least be a prespan about what time the data series starts and likely also what data that is, renge of values, perhaps, and more info.
Many chunks of the file will perhaps be 4 byte binary values, that could be the case, it could also be floating point numbers with a legth of 8 bytes or more. VFP has some functions for converting binary to values like CTOBIN(), which has some options to coinvert words (2 byte length) or normal integers 4 bytes, signed or unsigned, but before you dive into all this:
You also see the EDF Downloads section
shows there is more software than just OSCAR to deal with EDF data and before you reinvent the wheel I'd look into that software list and what it can do for you or others in the forum you want to work for.
There's no simple decoding of binary, binary is just the bits, you have to know what to expect where in a file to interpret a binary file correctly and there's no decoding information included that a general filestream function would use to produce "human readable" or otherwise simpler to understand data. You expect too much automatisms about this to exist just looking for another way to reda in the files. As said, the bytes are the bytes, no matter how you read them.
I think you could add yourself into the list and provide yet another software solution, okay, but this could carry you away into many different details aside frm the main data series in these files and the different formats EDF and EDF+ and whatever other formats other watches or devices produce.
With the limited concepts you have about reading files, it's a steep learning curve ahead, going into very detailed things as how data types are stored. Even a simple type as an integer can be stored with lowest significant byte first or last, aka as endianness.
You'll put yourself into elementary computer science classes, not to discourage you, but it can get very fiddly and then without guarntuee to be able to generally decode any EDF or EDF+ files.
Chriss