ameedoo3000
IS-IT--Management
hi all ( ramadan kareem )
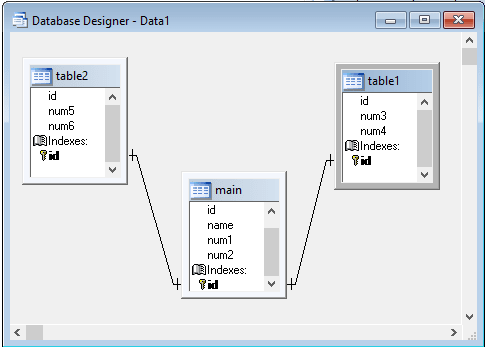
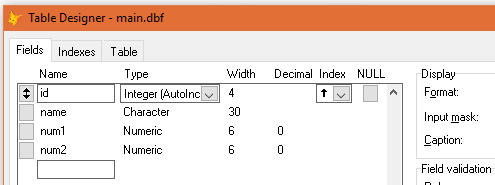
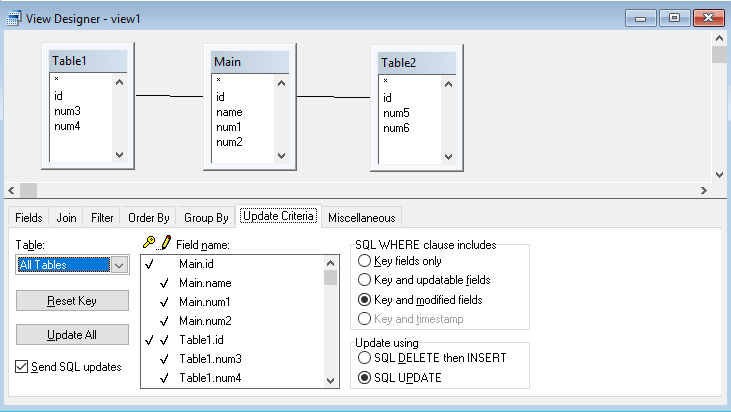
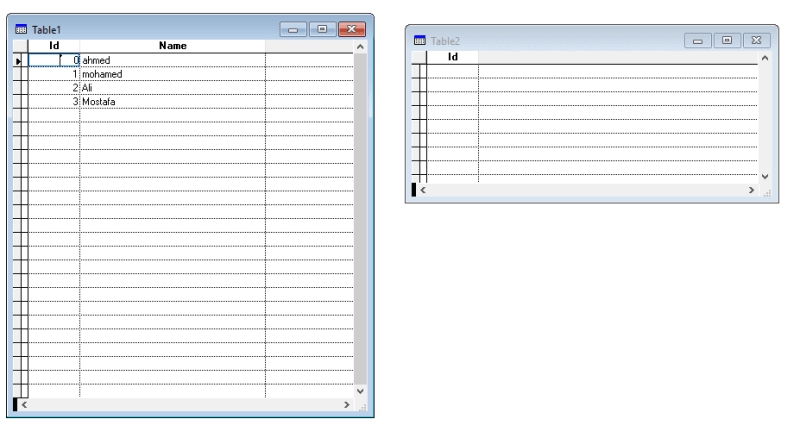
i want to ask how can i replace all filed data from any table to another filed in another table ( table1.id to table2.id )
Greetings
Ahmed
i want to ask how can i replace all filed data from any table to another filed in another table ( table1.id to table2.id )
Greetings
Ahmed