If you don't have a backup you disappoint me, Dennis. There's a reason for backups, especially also of the DBC/DCT/DCX files. If a DBC doesn't change all that often, an older backup would do, the data of the DBC is almost static, ideally it is completely static, but of course from time to time you extend your data with new fields or tables. For a stable DBC you should refrain of daily adding and removing temporary tables or indexes or fields etc, that wears the DBC files as any other DBF, but if it's static nothing happens to it corrupting it.
Just restoring the DBC/DCT/DCX and all your tables are back in it.
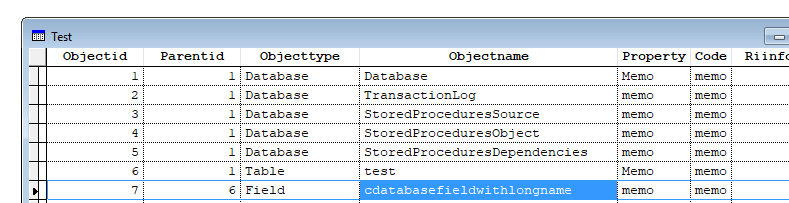
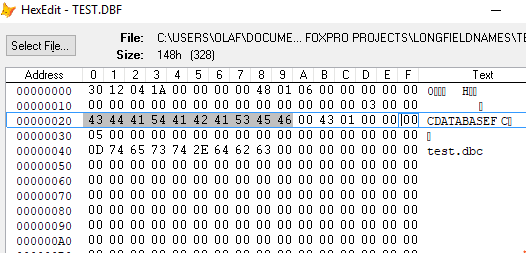
When you now CREATE DATABASE new.dbc and use ADD TABLE to add back all tables you have them with shortened names, you might get an error, as they are not free, they have their DBC back reference.
The only place where you find your long field names and default values and some other stuff is the DBC, there is no redundancy about the metadata when you don't create it by either backup or the other opportunity: gendbc. Gendbc is creating a script to recreate your dbc. In cases, you forget to let it be up to date by redoing it after each dbc version upgrade you have a better chance in adding latest modification in its code than you have restoring an outdated dbc/dct/dcx file triple. That's why that is preferable, but also more work to just copy these files in backups. One thing bad about GenDBC is it doesn't preserve any subfolder structure you might have for your tables. I think gendbcx does that, it's in vfpx (github) but too late for this case, just a tip for the future. It obviously also doesn't take into account any free dbfs you have with some extra config or other data and any different files and file types you may only refer to in your data by a path.
And no, REINDEX is not bad. Yes, if CDX header is broken, REINDEX won't save it. It's not a metadata repair. But even if you just backup the cdx files of empty tables, right after their creation, or ANY state of them, that's healthy, you can copy that back and REINDEX and your indexes are complete and up to date again. In case of DBC you don't need that DCX backup, as the indexes are defined equally for all DBC, it is one and the same table strucure of all DBCs, all headers of dbc and dcx files of VFP databases are 1:1 equal Just the FPT file (DCT) has no static header, that's simply because already the first 4 bytes point to the first free block and that's not static data.
So you can just create a new DBC and take it's DCX file to your corrupt DBC and REINDEX it while you opened it by USE your.dbc, your index data is repaired. If that's the only thing tha was corrupt you can get back there. At least if you still have a copy of the initial state of your corrupted dbc before you began your repair efforts.
All that should be really known to regulars, as I and others more than once gave all these tips.
Bye, Olaf.
![[hammer]](/data/assets/smilies/hammer.gif "[hammer] [hammer]")