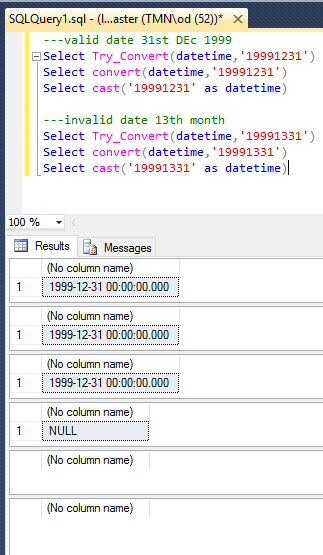
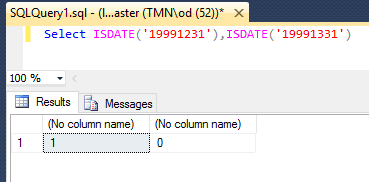
Need to clean several large pipe delimited text files prior to import into a newly created Sql Server 2012 database.
The plan is to load the Sql Server database and then append data to the database on a monthly basis.
Each text file contain 500,000 to 850,000 records with over 50 columns. Also, there are three date columns in the format YYYYMMDD.
Specifically, I need to review and clean each text file. Cleaning include;
1. Extract records that have a zero in the any of the three date columns.
2. Extract records that have zeroes in the Month and Day portion of the date. (for example, has a format like "20160000").
Initially, I opened the text files using MS Excel but then researched the use of a text editor that can/should be used.
Downloaded and installed the following text editors - GVIM, Sublime Text, and EmEditor. Upon opening the largest text file in each of the editors, I was not readily able to display the data in a columnar format that would facilitate a review of the records.
Based on my experience with MS Excel, It appears that editing the text files using MS Excel would be convenient and relatively easy compared to the use of the text editors.
Did also create the Create Table and Bulk Insert Sql Scripts to load the database(prior to cleaning of the text files). All of the tables were loaded except one. The one table that was not loaded failed because of records that have zeroes in the Month and Day portion of the date. (for example, has a format like "20160000").
Any insight as to the preferred method to clean the text files so I can initially load the Sql Server database?
Any additional insight as to the use of SSIS or Bulk Insert to perform the intial loading of the database and the subsequent appending of data on a monthly basis that will enable the storing of all records with errors in a "temporary" table and just load records that do not have errors?
The plan is to load the Sql Server database and then append data to the database on a monthly basis.
Each text file contain 500,000 to 850,000 records with over 50 columns. Also, there are three date columns in the format YYYYMMDD.
Specifically, I need to review and clean each text file. Cleaning include;
1. Extract records that have a zero in the any of the three date columns.
2. Extract records that have zeroes in the Month and Day portion of the date. (for example, has a format like "20160000").
Initially, I opened the text files using MS Excel but then researched the use of a text editor that can/should be used.
Downloaded and installed the following text editors - GVIM, Sublime Text, and EmEditor. Upon opening the largest text file in each of the editors, I was not readily able to display the data in a columnar format that would facilitate a review of the records.
Based on my experience with MS Excel, It appears that editing the text files using MS Excel would be convenient and relatively easy compared to the use of the text editors.
Did also create the Create Table and Bulk Insert Sql Scripts to load the database(prior to cleaning of the text files). All of the tables were loaded except one. The one table that was not loaded failed because of records that have zeroes in the Month and Day portion of the date. (for example, has a format like "20160000").
Any insight as to the preferred method to clean the text files so I can initially load the Sql Server database?
Any additional insight as to the use of SSIS or Bulk Insert to perform the intial loading of the database and the subsequent appending of data on a monthly basis that will enable the storing of all records with errors in a "temporary" table and just load records that do not have errors?