Can you just unzip the xlsx manually (after adding the extension zip or using any archiver that detects a zip archive from it's inner structure, like 7zip).
And then run this?
Code:
? '"' $ filetostr(getfile('workbook.xml'))
You can find the workbook.xml file inside the unzipped folder structure with the workbookname as folder name and a subfolder called xl, so:
[pre]somedrive:\xlsxcontainingfolder\workbookname\xl\workbook.xml[/pre]
As that must be valid XML, no matter if office XML or any other, the few characters we mentioned already must be escaped by HTML entities (like " or &
")
. It also doesn't become wrong XML, if the characters are twice HTML encoded, therefore and as you get out '"', for example, where you expect just ", you would find " within the XML file before it's read out by Greg's VFPxWorkbookXLSX class.
If that's the xml contains a double escaped ", which would not point out whether it's intentional or not. It also still is valid XML, but you'd finally know the source of this is not an error in Greg's reader, he escapes it once, not twice, and that's also correct, if you store a HTML entity into a cell, i.e. when you open up excel and explicitly write in " or write in a fully qualified mail address in HTML escaped format, then you do have " within the excel cell and you will have " in the XML of the excel cell and you'd want to also get back the HTML entity, not let a reader unescape it until there are not HTML entities. That means it's not the job of an XML reader to un-escape such HTML entities until they are gone. Because XML must not only be capable to store ", but also to store ", which means storing that as " and getting back ", not ".
See? The HTML entities just as the more usual backslash escape mechanism also must allow to be able to encode escape characters or sequences themselves. Therefore it also isn't strictly pointing out an error, that you read out ", that's only an error if there's no " in the xml file with the workbook data itself.
Caution, though, there's a chance the workbook.xml only contains reference values of content stored in another file of the xlsx archive. So a .f. also is not necessarily pointing out Greg's class has an error.
Besides all this, alone Greg's test proves well enough there is no wrong reading back of what's in the XML cells. So it would be a very special complex case like XML is stored in a Unicode format with double byte characters, instead of utf-8, which is the default for most XML and within normal letters and some more characters including & and ; is just single byte characters. Also, in that case I would expect the output to contain chr(0), too, if it's not decoded to ANSI.
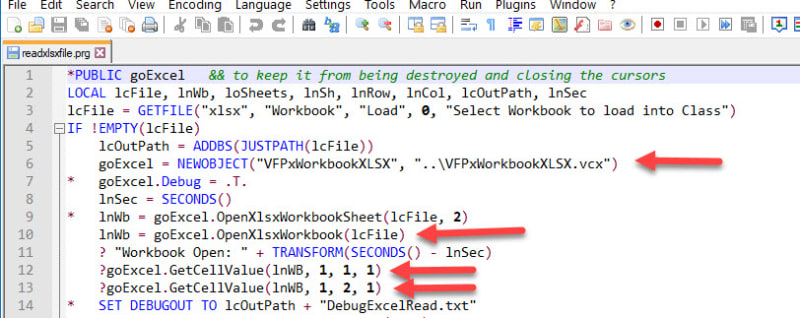
As we also still have no clue what exact code you're using to read out a cell value, it's hard to say what could have gone wrong. Your posts indicated that you at least tried to use the protected methodds GetXMLString, which could work once you changed the mwethod to be public in the class, but then would correctly not unescape anything. You have to use the GetCellValue method. If you "hacked" the class to be able to use GetXMLString, you stepped on your own foot. GetXMLString, with the emphasis on XML, returns the escaped cell value, including " for ", because " is reseved in XML to be the ddelimiter of attributes of XML tags. So while in itself the " character can of course be within an XML file, it's escaped in XML values. Otherwise " would end an attribute and cause all kinds of parsing errors.2
Overall, Rajesh, I think you understand the nature of escaping characters, you just haven't thought down to the bottom of it. I hope this time I explained it in enough detail so it became clear why and how such characters are escaped, and that a feature like unescaping HTML entities automaatically until no more are left is counterproductive. It would help your case, but not be generally correct XML parsing.
Chriss
 rivatemethod() or have another private method that does so. That way you overcome the unfortunate implementtion of protected in VFP. It shoudn't be necessary to do that, though. The developer using a class should be responsible for knowing or at least learning OOP principles once you don't understand why an obviously existing method is said to not exist.
rivatemethod() or have another private method that does so. That way you overcome the unfortunate implementtion of protected in VFP. It shoudn't be necessary to do that, though. The developer using a class should be responsible for knowing or at least learning OOP principles once you don't understand why an obviously existing method is said to not exist.