Hi,
I have a VFP9 web application where I want to add support for the Czech language. It all works fine except for the reports. If Czech words are entered via the web interface, they are stored in the table like this:
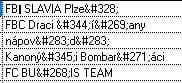
When I list these words again in the web browser, it looks perfectly fine, like this:
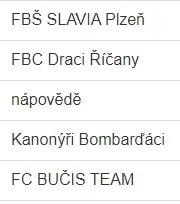
The problem is in the reports where the contents of the table is listed except for a couple of letters like for example "Š" that are actually shown correctly:

My current codepage is 1252 and I have tried other codepages, STRCONV(), etc, but I can never get VFP to show the original texts again. Is information lost once the words are written to the table? If so, how come that the web browser is able to show it correctly? Any hints how to get the reports to show the original texts?
BR,
Micael
I have a VFP9 web application where I want to add support for the Czech language. It all works fine except for the reports. If Czech words are entered via the web interface, they are stored in the table like this:
When I list these words again in the web browser, it looks perfectly fine, like this:
The problem is in the reports where the contents of the table is listed except for a couple of letters like for example "Š" that are actually shown correctly:
My current codepage is 1252 and I have tried other codepages, STRCONV(), etc, but I can never get VFP to show the original texts again. Is information lost once the words are written to the table? If so, how come that the web browser is able to show it correctly? Any hints how to get the reports to show the original texts?
BR,
Micael
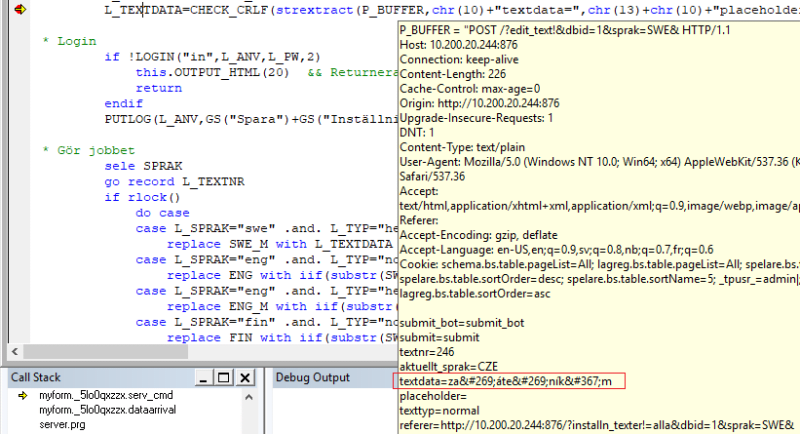

") in the incoming data, so you spare the conversion of that, you only need the STRCONV(input,11) to the then current codepage 1250.
in the incoming data, so you spare the conversion of that, you only need the STRCONV(input,11) to the then current codepage 1250.