MgtHargreaves
Programmer
I think it is fair to say that in this situation, it would be expected that the index needs to be recreated. However, we have a situation where the index is actually correct, but the data is wrong. It came to light because the customer ran a routine which did a pack, and therefore the index was recreated. Because of the duplicate records, the index was deleted.
Looking in the data (not sorted), we have 3 records with identical information in a field which is the primary key :

These 3 records are duplicated - every single field has exactly the same information.
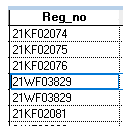
Reading the data using the primary key index, we get :

Is it possible to find the actual value of the field in the index ?
Thank you
Margaret
Looking in the data (not sorted), we have 3 records with identical information in a field which is the primary key :
These 3 records are duplicated - every single field has exactly the same information.
Reading the data using the primary key index, we get :
Is it possible to find the actual value of the field in the index ?
Thank you
Margaret