The table looks like this
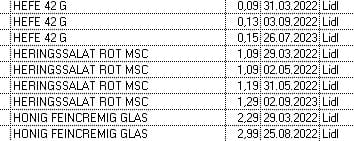
The columns from left to right are
product, price, date of input, vendor
The list is sorted by product and their date of input
I would like to find in this sample
only the products with their last input (the youngest input by product)
In this sample it would be
record no 3 (Hefe)
record no 7 (Heringssalat)
record no 9 (Honig)
and only that must to be shown in a new view.
Thanks for the correct select/scan command.
Klaus
Peace worldwide - it starts here...
The columns from left to right are
product, price, date of input, vendor
The list is sorted by product and their date of input
I would like to find in this sample
only the products with their last input (the youngest input by product)
In this sample it would be
record no 3 (Hefe)
record no 7 (Heringssalat)
record no 9 (Honig)
and only that must to be shown in a new view.
Thanks for the correct select/scan command.
Klaus
Peace worldwide - it starts here...

