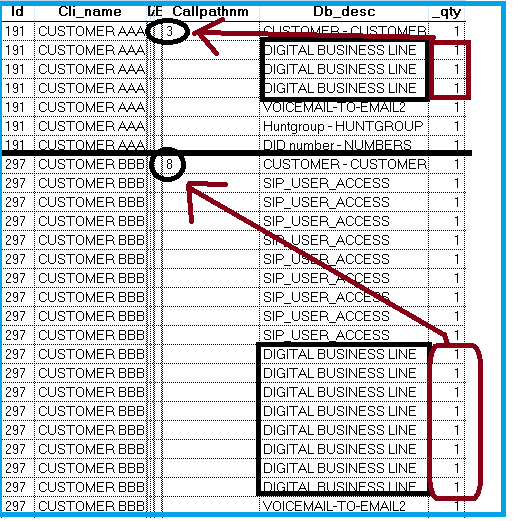
Hi everybody,
I need a simple optimization for these 4 lines of code. I would like to have it into 1 command instead (if possible). These are the 4 lines of code:
USE C:\union\BOUNCE_SUP990\SOURCE
sele id, VAL(callpathnm) as cps from C:\union\bounce_sup990\source WHERE val(callpathnm)>0 into table r:\digibuzlines
SET RELATION TO Source.id INTO Digibuzlines ADDITIVE
REPLACE source._qty with digibuzlines.cps FOR source.db_desc='DIGITAL BUSINESS LINE' AND source.id = digibuzlines.id
I'm trying to turn it into only 1 UPDATE command, so I've tried the: UPDATE C:\union\bounce_sup990\source SET.... command but the result isn't updating correctly.
Can someone please help me with this quick optimize ?
Thanks,
FOXUP
I need a simple optimization for these 4 lines of code. I would like to have it into 1 command instead (if possible). These are the 4 lines of code:
USE C:\union\BOUNCE_SUP990\SOURCE
sele id, VAL(callpathnm) as cps from C:\union\bounce_sup990\source WHERE val(callpathnm)>0 into table r:\digibuzlines
SET RELATION TO Source.id INTO Digibuzlines ADDITIVE
REPLACE source._qty with digibuzlines.cps FOR source.db_desc='DIGITAL BUSINESS LINE' AND source.id = digibuzlines.id
I'm trying to turn it into only 1 UPDATE command, so I've tried the: UPDATE C:\union\bounce_sup990\source SET.... command but the result isn't updating correctly.
Can someone please help me with this quick optimize ?
Thanks,
FOXUP