-
2
- #1
Olaf Doschke
Programmer
I just wrote a FAQ about UTF-8 string encoding validation, see faq184-7900.
Bye, Olaf.
Bye, Olaf.
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
LOCAL lcSomestring
* the normal way to STRCONV
lcSomestring = ''+0he4f6fcdf
? "initially ANSI:"+lcSomestring
lcSomestring = STRCONV(lcSomestring,9)
? "converted to UTF-8 once:"+lcSomestring
lcSomestring = STRCONV(lcSomestring,9)
? "converted to UTF-8 twice:"+lcSomestring
lcSomestring = STRCONV(lcSomestring,9)
? "converted to UTF-8 three times:"+lcSomestring
? "single reconverted to ANSI:"+STRCONV(lcSomeString,11)
? "double reconverted to ANSI:"+STRCONV(STRCONV(lcSomeString,11),11)
? "triple reconverted to ANSI:"+STRCONV(STRCONV(STRCONV(lcSomeString,11),11),11)
? "result: every conversion and reconversion changes the string"
? "-----"
* the 'definite' way to validate and only eventually STRCONV
lcSomestring = ''+0he4f6fcdf
? "initially ANSI:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 once:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 twice:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 three times:"+lcSomestring
? "result: the first conversion is stable"
? "-----"
* where the 'definite' conversion fails
lcSomestring = ''+0he4f6fcdf
? "initially ANSI:"+lcSomestring
lcSomestring = STRCONV(lcSomestring,5)
? "converted to Unicode once:"+lcSomestring
lcSomestring = STRCONV(lcSomestring,5)
? "converted to Unicode twice:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 once:"+lcSomestring
? "result: the final UTF-8 conversion doesn't remove unnecessary Unicode 0 bytes, as they are valid UTF-8 chars, too."
? "-----"
lcSomestring = ''+0he4f6fcdf
? "initially ANSI:"+lcSomestring
lcSomestring = STRCONV(lcSomestring,5)
? "converted to Unicode once:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 once:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 twice:"+lcSomestring
? "result: at least the final UTF-8 is stable."
? "-----"
lcSomestring = ''+0hc3a4f6fcdf
? "initially partial UTF-8:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 once:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 twice:"+lcSomestring
lcSomestring = IIf(ValidateUtf8(lcSomestring )=0, lcSomestring ,StrConv(lcSomestring ,9))
? "converted to 'definite' UTF-8 three times:"+lcSomestring
? "result: the first conversion is stable, but the single already UTF-8 converted '"+0hc3a4+"' is still getting double converted."For lnCounter = 1 To m.lnStringBytes
lnFirstByte = Asc(Substr(m.tcString, m.lnCounter, 1))
If m.lnFirstByte<0x80 && that's ok and identical to ASCII
Loop
Endif
*...
EndFor#Define cnStep 10000
Local lnLen, lcString, lcChar, lnT0, lnT
Create Cursor crsTiming (nLen I, nSeconds B)
For lnLen = cnStep To 30*cnStep Step cnStep
lcString = Space(lnLen)
lnT0 = Seconds()
For lnCounter = 1 To m.lnLen
lcChar = Substr(m.lcString, m.lnCounter, 1)
Endfor
lnT = Seconds()-lnT0
Insert Into crsTiming Values (lnLen/cnStep, lnT)
Endfor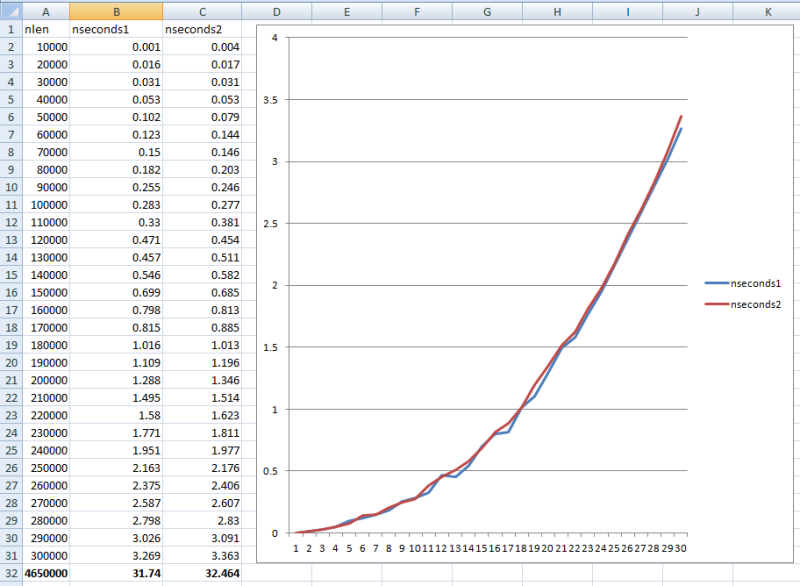
#Define cnStep 10000
Local lnLen, lcString, lcChar, lnT0, lnT, lnRest, lcBuffer
Create Cursor crsTiming (nLen I, nSeconds B)
For lnLen = cnStep To 30*cnStep Step cnStep
lcString = Space(lnLen)
lnRest = lnLen
lnCounter = 0
lcBuffer = ''
lnT0 = Seconds()
Do While lnCounter < m.lnRest
lnCounter = lnCounter + 1
If lnCounter+5 > Len(m.lcBuffer) And Len(m.lcString)>0
lcBuffer = Substr(m.lcBuffer, lnCounter) + Left(m.lcString, 1000)
lcString = Substr(m.lcString, 1001)
lnCounter = 1
lnRest = Len(m.lcBuffer)+Len(m.lcString)
Endif
lcChar = Substr(m.lcBuffer, m.lnCounter, 1)
Enddo
lnT = Seconds()-lnT0
Insert Into crsTiming Values (lnLen/cnStep, lnT)
Endfor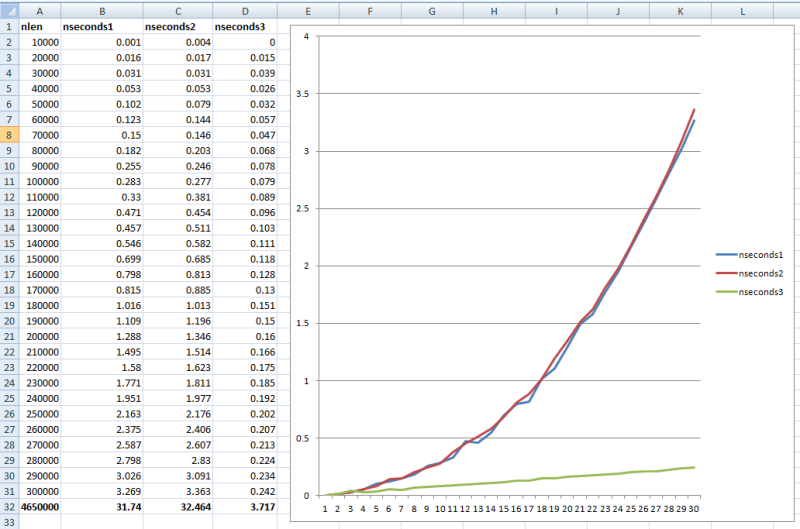
#Define cnStep 10000
Local lnLen, lnStringPtr, lcChar, lnT0, lnT
Create Cursor crsTiming (nLen I, nSeconds B)
apideclare()
For lnLen = cnStep To 30*cnStep Step cnStep
lnStringPtr = HeapAlloc(gnHandle,0, @lnLen)
* It's not necessary to initialize ther allocated memory
* for this performance test, but we do so outside of
* time measuring anyway:
=RtlMoveMemory(lnStringPtr, Space(lnLen), lnLen)
lnT0 = Seconds()
For lnCounter = 0 To m.lnLen-1
lcChar = Sys(2600,lnStringPtr+m.lnCounter,1)
Endfor
lnT = Seconds()-lnT0
HeapFree(gnHandle, 0, lnStringPtr)
Insert Into crsTiming Values (lnLen/cnStep, lnT)
EndFor
HeapDestroy(gnHandle)
#DEFINE SwapFilePageSize 4096
#DEFINE BlockAllocSize 8192
Procedure apideclare()
Public gnHandle
DECLARE INTEGER HeapCreate IN WIN32API ;
INTEGER dwOptions, ;
INTEGER dwInitialSize, ;
INTEGER dwMaxSize
DECLARE HeapDestroy IN WIN32API ;
INTEGER hHeap
DECLARE INTEGER HeapAlloc IN WIN32API ;
INTEGER hHeap, ;
INTEGER dwFlags, ;
INTEGER dwBytes
DECLARE INTEGER HeapFree IN WIN32API ;
INTEGER hHeap, ;
INTEGER dwFlags, ;
INTEGER lpMem
DECLARE RtlMoveMemory IN WIN32API ;
INTEGER nDestBuffer, ;
STRING @pVoidSource, ;
INTEGER nLength
* usage
gnHandle = HeapCreate(0, BlockAllocSize, 0)
* HeapAlloc(gnHandle,0, @nPtr)
* HeapFree(gnHandle, 0, nPtr)
* =RtlMoveMemory(nPtr, cSource, Len(cSource)) && take care len<=alloc size
* HeapDestroy(gnHandle)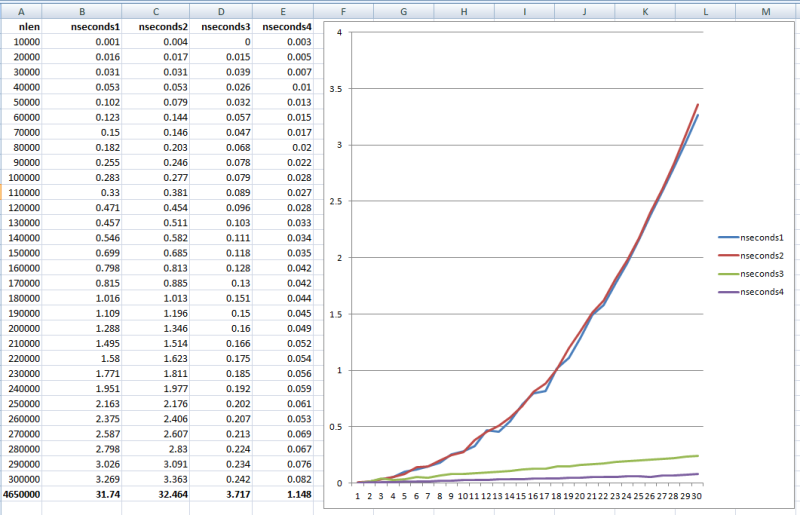
FUNCTION ValidateUTF8x (UTF8 AS String) AS Boolean
RETURN STRCONV(STRCONV(m.UTF8,12),10) == m.UTF8
ENDFUNCLOCAL BadUTF8 AS String
LOCAL CorrectedUTF8 AS String
LOCAL GoodSegment AS String
LOCAL SoFarSoGood AS String
LOCAL ErrorLocation AS Integer
LOCAL ARRAY GoodSegments[1]
LOCAL BadMark AS String
m.BadMark = CAST(0hefbfbd AS Char(3))
m.BadUTF8 = FILETOSTR(GETFILE())
m.CorrectedUTF8 = STRCONV(STRCONV(m.BadUTF8, 12), 10)
ALINES(m.GoodSegments, m.CorrectedUTF8, 2, m.BadMark)
m.SoFarSoGood = ""
FOR EACH m.GoodSegment IN m.GoodSegments
m.SoFarSoGood = m.SoFarSoGood + m.GoodSegment + m.BadMark
IF !LEFT(m.BadUTF8, LEN(m.SoFarSoGood)) == m.SoFarSoGood
m.ErrorLocation = LEN(m.SoFarSoGood) - LEN(m.BadMark) + 1
? m.ErrorLocation
? SUBSTR(m.BadUTF8, m.ErrorLocation, 6), CAST(SUBSTR(m.BadUTF8, m.ErrorLocation, 6) AS W)
RETURN
ENDIF
ENDFOR
? -1Yes, you remember that correctly.atlopes said:accessing variables and parameters requires locking
stringptr = _HandToPtr(val.ev_handle);
address = (long) &stringptr;
_RetInt(address, 10);#Define cnStep 100000
SET LIBRARY TO string.fll
For lnLen = cnStep To 5*cnStep Step cnStep
lcString = Space(lnLen)
lnByte = 0
lnT0 = Seconds()
SubInit("lcString","lnByte")
For lnCounter = 1 To m.lnLen/4
SubByte()
EndFor
FreeHandles()
lnT = Seconds()-lnT0
Insert Into crsTiming Values (lnLen/cnStep, lnT)
EndFor