In short summary, directly answering your question: No. While isn't optimized with or without NOOPTIMIZE clause.
This section of a Rushmore optimization help topic describes it:
VFP help said:
Operating Without Rushmore Query Optimization
Data retrieval operations proceed without Rushmore optimization in the following situations:
When Rushmore cannot optimize the FOR clause expressions in a potentially optimizable command.
When a command that might benefit from Rushmore contains a [highlight #FCE94F]WHILE[/highlight] clause.
When memory is low. Data retrieval continues, but is not optimized
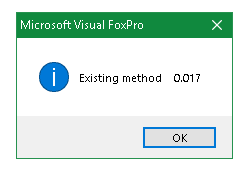
So not using Rushmore has already been decided by using the WHILE scope.
So to twist the question a bit: Can this be speed up by Rushmore? Maybe, but surely not by just removing the NOOPTIMIZE clause.
Removing the SEEK and just doing SUM prj_hours to total_prjhours FOR project_id = cur_projid would use Rushmore.
The steps are (in general):
Find usable indexes for the FOR conditions
Create Rushmore bitmaps, if memory allows (setting SYS(3050))
Combine Rushmore bitmaps due to boolean algebra operations in the single terms of the FOR clause
Visit the record according to the bits of the result Rushmore bitmap.
The overall goal is least read access of the DBF by first knowing which recnos fulfill the for condition.
If you SEEK in proj_id order, the WHILE or REST scope are ideal and need no Rushmore. It will also depend on the number of records how you actually profit from knowing the recnos from the ruhmore optimization steps vs needing to traverse the index tree node by node intil there is no same valued sibling anymoe.
In your sepcial case, the conditions that Rushmore is just overhead are easily met. First, you only make use of one Rushmore bitmap as there only is one condition on the proj_id. Let me make the assumption one project_id makes less than 1% of all your data, then Rushmore still has to first create a bitmap with 1 bit for each record (also for those not matching), and while it only needs 1 bit per record and todays RAM memory not rarely allows you to take away 2GB for your VFP app, this still might be time better spent on traversing the index tree nodes more directly without even building up one Rushmore bitmap.
You could simply experiment and try out this instead:
Code:
Select Sum(prj_hours) from PrjTime Where project_id = cur_projid into array total_prjhours
? total_prjhours
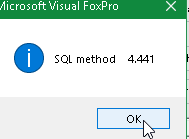
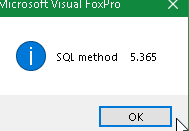
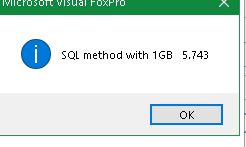
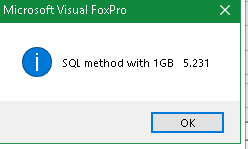
That is SQL that will use Rushmore (Unless you SET OPTIMIZE OFF).
But you know (now) in the SUM command with a WHILE scope, NOOPTIMIZE is not doing anything, removing it also won't add Rushmore optimization usage, as the WHILE clause can't foresee which bits in a Rushmore bitmap mean consecutive records in the index order (that's what WHILE or also REST need). The bits in a Rushmore bitmap are always in physical (recno) order and when you add records for multiple employees and projects the records of one project are usually in chronological order but still records of other projects are scattered in between, so usually the bits of one proje_id are concentrated in a range relating to the project start and end, but scattered with records of other projects.
And with that in mind it's most timesaving to sum all projects or all active projects in one go, then you just build up multiple sum records and these can be built in parallel using every single record accessed in physical order. Then there also is no need to know which records to access, simply all or the tail of records starting from a known first record off all active projects.
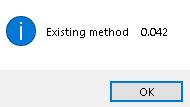
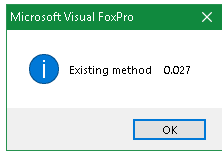
Whatever your actual data situation is would determine what's best, but the reasoning to use NOOPTIMIZE wasn't bad, when the programmer adding it didn't know WHILE prevents Rushmore anyway. When you take it into your own hands to SEEK to the first record and then SUM or SCAN WHILE or REST you actually don't want Rushmore to need to build a bitmap, you want to traverse data by traversing the index.
There is one advantage of knowing recnos from Rushmore, not only when multiple Rushmore bitmaps are combined: You know the valid records in recno order and can visit them in that order. The advantage is lost with SSD drives, but the most modern platter drive controllers also use a technique to cache more than you actually read at first in case a later read needs data from the same sector and or they organize reads depending on head position and rotation speed and prediction of what sectors you may read. But that's also all "madness" of the past without random SSD access. Let alone the situation a file is cached in memory and you use the random access feature that gives RAM its name.
I don't say Rushmore is bad, but it only really shines, if you need to get a bigger portion of data or have several not very selective conditions that combine to a very select few result records to finally actually fetch only those. Ironically Rushmore will be fastest whenever the result or an intermediate bitmap is empty and no further boolean agebraic condition could add bits in the final bitmap (OR conditions, for example).
All the cdx access for getting there needs to be faster and less than without any index at all to break even with the simpler nooptimization strategy. Again this sounds worse for Rushmore than it is, because of a very simple reason: If Rushmore would only speed up the most complex cases, MS could have dropped it overall. There usually is a benefit.
In your special case I see a better fit in aggregating sums of multiple projects at once, that does the job better than repeating it for each project id. I think I also already said that in an earlier question you asked. And you can actually forget anything, when your data is so small, that keeping it cached is easily done and you won't notice much difference even without indexing at all.
Chriss