-
2
- #1
Chris Miller
Programmer
Hello Steve, Klaus and anyone interested.
I had a stab at reading in the addresses mentioned in thread184-1810484.
I took a lot of the code I already had in there from myself and others, but first I tried to find a way to split the large ~4.5 GB pp-complete.csv
Here Powershell proves to do this in a 1-liner, credit goes to Stephan Solomonidis blog article:
In short I used this at the Powershell prompt:
In the first run I didn't have the utf8 and Powershell then by default outputs a Unicode encoding needing 2-4 byte per character (I think UCS2), which ended in about 12 GB of partial csv files. In theory you could output codepage 1252 to directly get the VFP default codepage, but on my machine Powershell denied to know that codepage.
By the way, this splits the pp-complete.csv into 262 files with each 99999 records, except the last file being a bit shorter. Overall after processing all these partial csv files I get a DBC summing up all files to ~2 GB. But I jump ahead. First of all I used Excel to read in the CSV and formatted the columns so the import into VFP is as easy as I showed in the other thread: By using a Range object you get out an array VFP can use in an SQL-Insert FROM ARRAY.
I tried to automate the OpenText Method and failed, didn't want to invest much into try&error and simply created an Excel template file with this Function:
This can be used from VFP to import the data with this routine:
I used atlopes import cursor definition and while I am also willing to try his CSVProcessor class, I coped with the slow performance of Excel but the ease of getting a range as an array.
It took a night to import it and the result is a neat DBC:
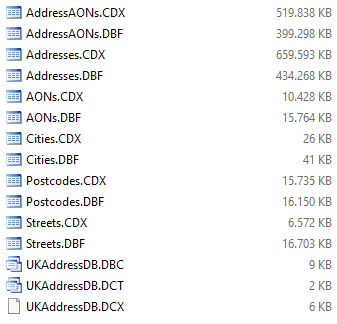
There are still some things to improve, for example the PAON/SAON data: Wherever you have just a normal (numeric, integer) house number Excel exports it with 10 decimal places, so the formatting of columns can be improved.
The major learnings from this is, data normalization isn't just important to have a generally accepted database design, but it takes out most redundancy and reduces the size even in comparison with the original CSV file.
I didn't import counties, districts localities and anything else I forget to mention, but you can easily extend the code to add more info. You could also foresee tales like CityPostcodes to store all valid combinations of City and Postcode, dito with streets, etc. So this data can also be used to confirm correct combinations. I think the 26 million addresses might not have all possible postcodes, so a pair you don't find in the price paid data might still exist, but you can confirm a lot of correct pairings of address detail information yourself, if that's the goal.
As the data contains prices paid you could also start to build up a UK map of rich and poor regions. Many things are possible. What I haven't yet tried is to use this data for some kind of address intellisense. I think I leave it at this, you can pick out what you like and proposed extensions and changes are welcome.
Chriss
I had a stab at reading in the addresses mentioned in thread184-1810484.
I took a lot of the code I already had in there from myself and others, but first I tried to find a way to split the large ~4.5 GB pp-complete.csv
Here Powershell proves to do this in a 1-liner, credit goes to Stephan Solomonidis blog article:
In short I used this at the Powershell prompt:
Code:
$i=0; Get-Content C:\data\pp-complete.csv -ReadCount 100000 | ForEach-Object{$i++; $_ | Out-File C:\data\pp-partial_$i.csv utf8 }In the first run I didn't have the utf8 and Powershell then by default outputs a Unicode encoding needing 2-4 byte per character (I think UCS2), which ended in about 12 GB of partial csv files. In theory you could output codepage 1252 to directly get the VFP default codepage, but on my machine Powershell denied to know that codepage.
By the way, this splits the pp-complete.csv into 262 files with each 99999 records, except the last file being a bit shorter. Overall after processing all these partial csv files I get a DBC summing up all files to ~2 GB. But I jump ahead. First of all I used Excel to read in the CSV and formatted the columns so the import into VFP is as easy as I showed in the other thread: By using a Range object you get out an array VFP can use in an SQL-Insert FROM ARRAY.
I tried to automate the OpenText Method and failed, didn't want to invest much into try&error and simply created an Excel template file with this Function:
Code:
Function openppdcsv(ByVal File As String) As Workbook
Workbooks.OpenText Filename:=File, Origin:=xlWindows, StartRow:=1, DataType:=xlDelimited, TextQualifier:=xlTextQualifierDoubleQuote, Comma:=True
Set openppdcsv = ActiveWorkbook
End FunctionThis can be used from VFP to import the data with this routine:
Code:
Close Tables All
Close Databases All
Cd Getenv("TEMP")
Erase *.Dbc
Erase *.dct
Erase *.dcx
Erase *.Dbf
Erase *.fpt
Erase *.Cdx
Create Database UKAddressDB
Create Table Cities (Id Int Autoinc Primary Key, City Char(30))
Index On City Tag City
Create Table Streets (Id Int Autoinc Primary Key, Street Char(50))
Index On Street Tag Street
Create Table Postcodes (Id Int Autoinc Primary Key, Postcode Char(8))
Index On Postcode Tag Postcode
Create Table AONs (Id Int Autoinc Primary Key, AON Char(25))
Index On AON Tag AON
Create Table Addresses (Id Int Autoinc Primary Key,;
StreetID Int References Streets Tag Id,;
CityID Int References Cities Tag Id,;
PostcodeID Int References Postcodes Tag Id)
Create Table AddressAONs (Id Int Autoinc Primary Key,;
AddressID Int References Addresses Tag Id,;
AONID Int References AONs Tag Id,;
PrimaryAON Logical)
#Define xlDelimited 1
#Define xlWindows 2
#Define xlLastCell 11
loExcel = Createobject("Excel.Application")
loExcel.DisplayAlerts = .F.
loExcel.Workbooks.Open("C:\data\pp-part_n.xlsm")
loExcel.Visible = .T.
Create Cursor Import (Identifier Char(38), Price Integer, TransferDate Date, Postcode Varchar(8) Null, ;
PropertyType Char(1), OldNew Char(1), Duration Char(1), ;
PAON Varchar(100) Null, SAON Varchar(100) Null, ;
Street Varchar(100) Null, Locality Varchar(100) Null, City Varchar(100) Null, ;
District Varchar(100), County Varchar(100), ;
Category Char(1), RecordStatus Char(1))
? DATETIME(), "Start"
For lnI = 1 To 262
lcFile = "C:\Programming\pp-addressdata\pp-partial_"+Transform(lnI)+".csv"
loWorkbook = loExcel.Run("openppdcsv", lcFile)
With loWorkbook.ActiveSheet
.Columns(1).NumberFormat = '@' && Identifier (Guid) -> Text
.Columns(2).NumberFormat = '0.00' && Price -> Number
.Columns(3).NumberFormat = 'yyyy-mm-dd;@' && TransferDate -> Date
.Columns(4).NumberFormat = '@' && Postcode -> Text
.Columns(5).NumberFormat = '@' && PropertyType
.Columns(6).NumberFormat = '@' && OldNew
.Columns(7).NumberFormat = '@' && Duration
.Columns(8).NumberFormat = '@' && PAON
.Columns(9).NumberFormat = '@' && SAON
.Columns(10).NumberFormat = '@' && Street
.Columns(11).NumberFormat = '@' && Locality
.Columns(12).NumberFormat = '@' && City
.Columns(13).NumberFormat = '@' && District
.Columns(14).NumberFormat = '@' && County
.Columns(15).NumberFormat = '@' && Category
.Columns(16).NumberFormat = '@' && RecordSatus
loLastCell = .Cells.SpecialCells( xlLastCell )
laData = .Range( .Cells(2,1), m.loLastCell ).Value
Endwith
For lnJ = 1 To Alen(laData)
If Vartype(laData[lnJ])="C"
laData[lnJ] = Strconv(laData[lnJ],11) && convert UTF-8 to Ansi
Endif
Endfor
Insert Into Import From Array laData
loWorkbook.Close(.F.)
ExtractAddressData()
Set Safety Off
Zap In Import
Set Safety On
Endfor lnI
Function ExtractAddressData()
ExtractCities()
ExtractStreets()
ExtractPostCodes()
ExtractAONs()
ExtractAddresses()
Endfunc
Procedure ExtractCities()
Select Distinct City From Import Into Cursor importCities
Scan
If Not Indexseek(City,.F.,"Cities","City")
Insert Into Cities (City) Values (importCities.City)
Endif
Endscan
Use In importCities
Procedure ExtractStreets()
Select Distinct Street From Import Into Cursor importStreets
Scan
If Not Indexseek(Street,.F.,"Streets","Street")
Insert Into Streets (Street) Values (importStreets.Street)
Endif
Endscan
Use In importStreets
Procedure ExtractPostCodes()
Select Distinct Postcode From Import Into Cursor importPostCodes
Scan
If Not Indexseek(Postcode,.F.,"Postcodes","Postcode")
Insert Into Postcodes (Postcode) Values (importPostCodes.Postcode)
Endif
Endscan
Use In importPostCodes
Procedure ExtractAONs()
Select Distinct PAON From Import Into Cursor importPAONs
Scan
If Not Indexseek(PAON ,.F.,"AONs","AON")
Insert Into AONs (AON) Values (importPAONs.PAON)
Endif
Endscan
Use In importPAONs
Select Distinct SAON From Import Into Cursor importSAONs
Scan
If Not Indexseek(SAON ,.F.,"AONs","AON")
Insert Into AONs (AON) Values (importSAONs.SAON)
Endif
Endscan
Use In importSAONs
Procedure ExtractAddresses()
Select Import
Scan
Indexseek(City,.T.,"Cities","City")
Indexseek(Street,.T.,"Streets","Street")
Indexseek(Postcode,.T.,"Postcodes","Postcode")
If !Empty(PAON)
Indexseek(PAON ,.T.,"AONS","AON")
AddressPAONID = AONs.Id
Else
AddressPAONID = 0
Endif
If !Empty(SAON)
Indexseek(SAON ,.T.,"AONS","AON")
AddressSAONID = AONs.Id
Else
AddressSAONID = 0
Endif
Insert Into Addresses (CityID, StreetID, PostcodeID) Values (Cities.Id, Streets.Id, Postcodes.Id)
If AddressPAONID >0
Insert Into AddressAONs (AddressID, AONID, PrimaryAON) Values (Addresses.Id, AddressPAONID, .T.)
Endif
If AddressSAONID >0
Insert Into AddressAONs (AddressID, AONID, PrimaryAON) Values (Addresses.Id, AddressSAONID, .F.)
Endif
EndscanI used atlopes import cursor definition and while I am also willing to try his CSVProcessor class, I coped with the slow performance of Excel but the ease of getting a range as an array.
It took a night to import it and the result is a neat DBC:
There are still some things to improve, for example the PAON/SAON data: Wherever you have just a normal (numeric, integer) house number Excel exports it with 10 decimal places, so the formatting of columns can be improved.
The major learnings from this is, data normalization isn't just important to have a generally accepted database design, but it takes out most redundancy and reduces the size even in comparison with the original CSV file.
I didn't import counties, districts localities and anything else I forget to mention, but you can easily extend the code to add more info. You could also foresee tales like CityPostcodes to store all valid combinations of City and Postcode, dito with streets, etc. So this data can also be used to confirm correct combinations. I think the 26 million addresses might not have all possible postcodes, so a pair you don't find in the price paid data might still exist, but you can confirm a lot of correct pairings of address detail information yourself, if that's the goal.
As the data contains prices paid you could also start to build up a UK map of rich and poor regions. Many things are possible. What I haven't yet tried is to use this data for some kind of address intellisense. I think I leave it at this, you can pick out what you like and proposed extensions and changes are welcome.
Chriss
